

JavaScript的工作原理
[Udemy课程|8章节内容]
[课程评价-⭐⭐⭐❎❎]
我认为这个章节的课程编排是有问题的,那些抽象性的知识完全可以合并到例子当中去讲,然后在例子说明完成后进行总结即可,如果先讲述理论性知识再讲例子最后总结实在过于冗余了。这太照顾新人了,如果是有基础的建议看mdn、知乎回答、B站详解视频来学习,这个章节没有动手的机会,基本都是理论知识,感到课程无聊是很难避免的,但是对求职、深入了解计算机和JavaScript都有很重要的意义。
JavaScript的定义
我们知道计算机需要CPU处理程序,需要内存储存变量等,C语言是一种"低级"语言,你需要手动地管理你的计算机资源,而JavaScript、Python等语言则不用担心,它们使用了所谓的抽象,使我们更加容易学习和使用,但是程序运行会变慢,所以JavaScript制造了一个强大的工具垃圾收集算法,它会自动删除未使用的对象以清理我们的内存。
JavaScript是一个多范式语言:
它即面向过程又面向对象还可以是功能性语言。
在JavaScript中几乎所有东西都是对象,除了原始值,比如:数字、字符串等。
数组不是原始值,数组是一个对象,数组从原型中创建数组,它含有数组需要的各种属性和方法以及接口。
JavaScript是一个并发模型,但为什么需要同时处理多个任务呢,那是因为JavaScript并发的同时也是一个单线程语言,这意味着它一次只能做一件事,那当我们遇到一个长期任务一直占着这个线程怎么办呢,所以我们在应用层上使多个事情排列发生,这些任务被切成一块一块全部挤向硬件层的单线程中处理,谁先处理完谁就先执行,这叫做事件循环。
因为当今计算机的处理速度非常快几乎几毫秒就可以处理一个任务,所以这使得单线程也可以看起来像同时执行完毕一样。
JavaScript的引擎
JavaScript引擎其实就是一个JavaScript代码的计算机程序,例如应用在chrome和node.js上的V8引擎。
JavaScript的runtime
一个JavaScript引擎总是包含一个调用栈(call stack)和一个堆(heap)。
调用栈是我们代码实际执行的地方,使用一个称为执行上下文的东西。
堆是一个非结构化的内存池,它存储了我们的应用程序需要的所有对象。
JavaScript在运行时,会包含一个回调队列,它是一个数据结构,包含所有准备执行的回调函数。例如我们添加一个事件处理函数给一个像按钮一样的DOM元素后,我们触发事件将会调用回调函数,它在事件发生后第一件事就是将回调函数放进了回调队列,当栈为空时回调函数被传递到栈以便它可以执行,这件事叫做事件循环(Ecent Loop)。
JavaScript的编译
编译与解释的区别:
编译时,整个源代码立即转换为机器码,然后编写此机器代码成为可以在任何计算机上执行的可移植文件,编译后你就可以在相应计算机上直接运行程序。
在解释中,有一个贯穿源代码始终的解释器并逐行执行,在执行前源代码被转换为机器码,然后就可以运行程序了。JavaScript曾经是一种纯解释型语言,但是解释型语言比编译语言慢得多。
现代的JavaScript引擎是两者混用的,它既可以编译也可以解释,这称为即使编译,这种方法基本编译了整个代码,将其立即转换为机器代码,然后立即执行,但是这次没有可移植文件可以执行。
所以当一串代码进入JavaScript引擎时是这样的:
源代码
|
V
解析代码(在解析的过程中,代码被解析成一个数据结构,称为抽象语法树或AST)
/*它首先拆分每一行代码,使其变成对语言有意义的片段,像const或function关键字,然后保存所以这些碎片以结构化的方式进入树中,此步骤还会检查是否含有任何语法错误,并且生成树以便稍后使用生成机器码。*/
|
V
编译----------------------------<----------------------------------
//它采用刚刚生成的AST把它编译成机器码,然后在该机器以及执行代码。 |
| |
V----------------------------->----------------------------------
执行(直到这里JavaScript的即刻编译还没有结束,这里创建的只是一个未优化的版本以使其立刻执行,在后台这段代码正在优化,并在已经运行的程序执行期间重新编译)
//执行发生在JavaScript引擎的调用栈中WEBAPIs
DOM、Timers、Fetch API ...
引擎和WEBAPIs其实不是一部分的,引擎提供运行的环境,而WEBAPIs提供功能,JavaScript只需要通过全局窗口对象(这就是为什么需要在一些方法前加上window.document的原因,这也是为什么Node.js只包含了引擎但没有WEBAPIs)访问这些API。
JavaScript代码是如何运行的?
全局执行上下文
当一个程序被编译后,执行时会创建一个全局的执行上下文(global object简称GO,也有叫全局执行上下文GEC的),它是一个顶级代码,基本不在任何函数中(所以在一开始,只有函数外的代码才会执行,而代码块内的代码不会执行,这就是之前说的“函数只能在调用时执行”),GO作为默认的EC存在,它是最终执行顶级代码的地方。
执行上下文
执行上下文(active object简称AO,也有叫函数执行上下文的FEC),每个函数被调用的时候,执行上下文将会被创建,其包含所有有必要的信息来运行该功能,方法也是一样,就是这些所有的上下文一起组成了之前的调用栈,在所有功能都执行完毕后,引擎将会一直等待回调函数到达以便它可以执行这些功能。
执行上下文中总是包含可变环境、当前环境的作用域链和this关键字。
执行上下文的运行
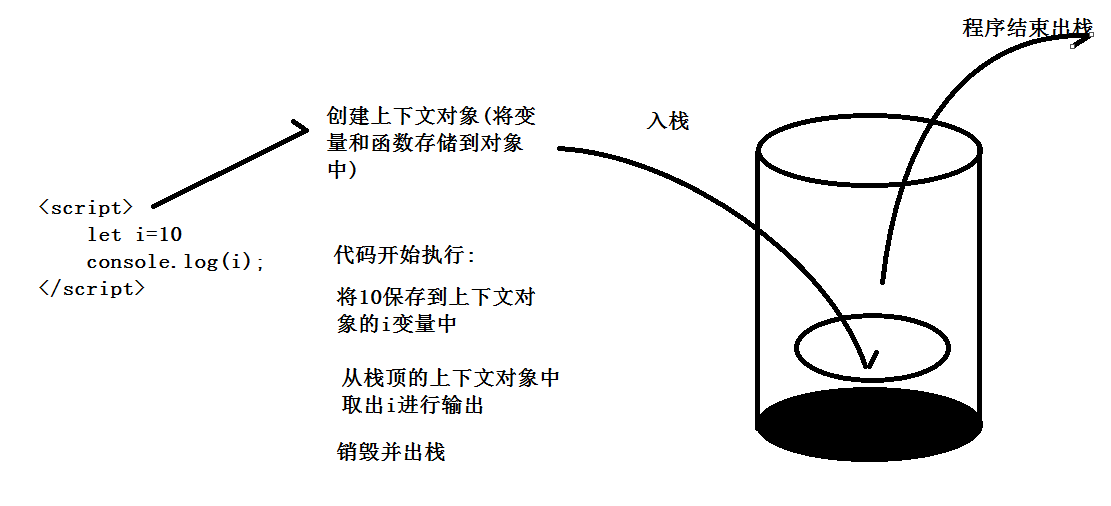
执行上下文中的内容
执行上下文包含一个可变环境,我们所有的变量、函数声明都被存储在这里面还有一个特殊的参数对象,这个对象包含所有进入当前执行上下文的函数传递的参数,因为每一个函数都拥有自己的执行上下文,所有全局上下文中也引用了函数和函数的执行上下文。
基本上所有的变量以某种方式在函数内部声明,最终进入可变环境,但是函数也可以访问函数外的变量,这之所以有效,是因为有一个叫做作用域链的东西,函数作用域或者块作用域里包含变量等信息,而它们通过作用域链被执行上下文的可变环境引用。
作用域与作用域链
作用域有三种:全局作用域、函数作用域和块作用域。
作用域是我们声明变量和函数的地方。
//全局作用域
const me = 'Jonas';
const jib = 'teacher';
const year = 1989;
//全局作用域中的变量可以在任何地方访问
//函数作用域
function calcAge(birthYear) {
const now = 2037;
const age = now - birthYear;
return age;
}
console.log(now); //这里会得到一个错误,因为在函数外访问不了函数内的变量,所以报了一个定义错误
//每个函数都会创建一个作用域以及该函数作用域中声明的变量
//函数作用域的变量只能在该函数内部访问
//函数作用域也被称为本地作用域
//块作用域
//块作用域在if、for等条件、循环控制语句中会有
//但是,块作用域只适用于let和const变量,var是可以被外部访问的,所以说var是不安全的
if (year >= 1981 && year <= 1996) {
const millenial = true;
const food = 'Avocado toast';
}
console.log(millenial); //这里会得到一个错误,因为在块外访问不了块内的变量,所以报了一个定义错误我们将在下面的代码中解释作用域以及构建范围链:
//全局作用域包含
//myName = 'Jonas'
const myName = 'Jonas';
//first函数的作用域引用
function first() {
//first函数作用域包含
//age = 30
const age = 30;
//块作用域的引用
if (age >= 30) {
//块作用域包含
//decade = 3
const decade = 3;
//millenial = true
var millenial = true;
}
//second函数作用域的引用
function second() {
//函数作用域包含
//job = 'teacher'
const job = 'teacher';
//这里引用了全局作用域的myName变量和first函数作用域的age变量,还使用了自己的job变量
consolo.log(`${myName} is a ${age}-old ${job}`);
}
sencond();
}
first();
//这些所谓的引用其实就是作用域链的工作方式
//作用域链的运作方式只能向上工作,不能横向工作
//如果一个变量在当前作用域中找不到,它就会去作用域链中查找,这个过程叫作变量查找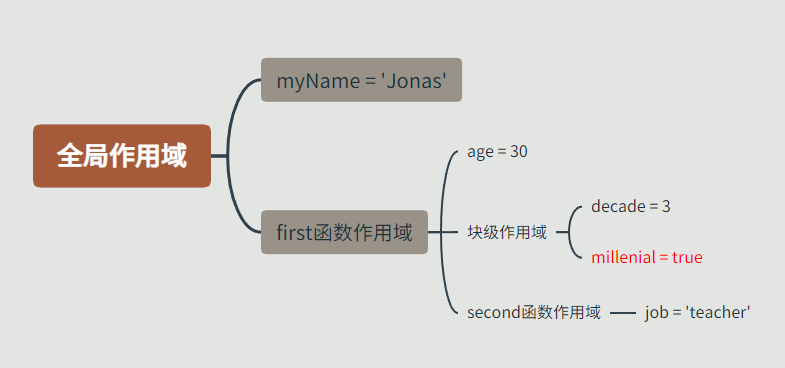
图中millenial变量标红,因为它是用var声明的,此用法不安全。
作用域链与调用栈的区别
总体来讲调用栈、执行上下文、可变环境和作用域是如何互相关联的。
const a = 'Jonas';
first();
function first() {
const b = 'Hello!';
second();
function second() {
const c = 'Hi!';
third();
}
}
function third() {
const d = 'Hey!';
console.log(d + c + b + a);
// ReferenceError
}在这里我们有三个函数,分别是first、second、third。
所以在这里我们的调用栈应该是这样的:
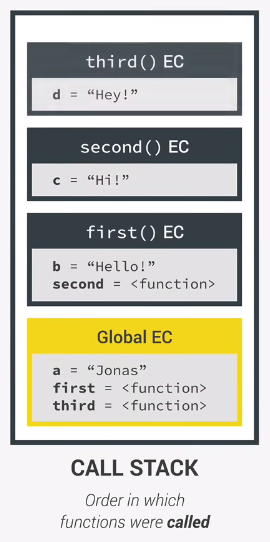
栈遵循先进后出的原则,具体看执行上下文的运行。
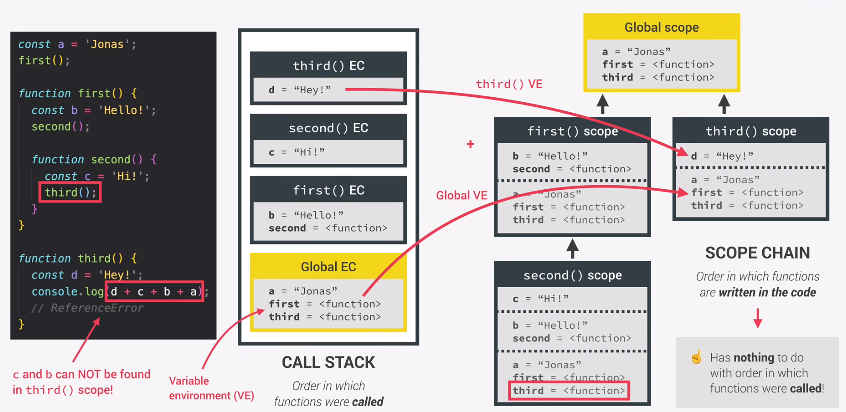
一个程序被编译后先创建EC(执行上下文)
每个EC(执行上下文)都有一个Variable environment简称VE(可变环境),例如:
Global EC(全局执行上下文)含有一个VE(可变环境)里面包含,具体看执行上下文的内容:
a = "Jonas"
first = <function>
third = <function>执行上下文完成创建后,我们现在需要创建作用域以及创建作用域链来链接(引用)上级元素的变量:
但是这里要注意作用域链与调用函数顺序无关,也就是说在作用域中的先后顺序跟程序中函数书写、调用的顺序没有一点关系,我记得是JavaScript引擎是根据自己的顺序排列的。
function second() {
const c = 'Hi!';
third();
}上面调用了third()函数,这是有效的,因为third()函数确实在second()函数作用域链中,third()是一个全局函数,因此它无处不在。
但是third()的consolo.log会报错,因为它无权访问次级、同级作用域的变量c、b。
所以都创建完毕是这样的:
提升(hoisting)
提升使某些类型的变量可访问或者说使我们的代码可用在代码实际声明它们之前。
在被执行前,代码被扫描进行变量声明,这些都发生在执行上下文的创建阶段,然后每个代码中的变量在可变环境对象中创建了一个新的属性。
通俗一点说,提升控制我们是否可以访问该变量
每个变量类型获得的提升不一样:
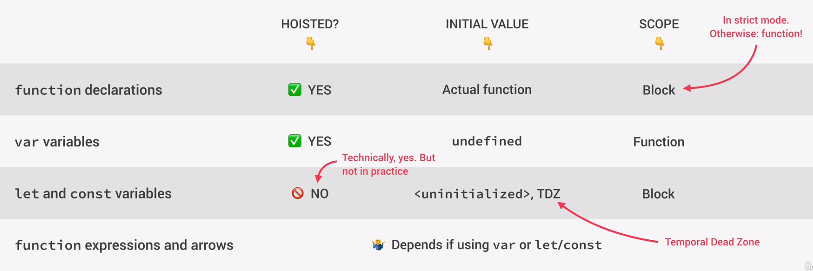
提升 | 初始值 | 作用域类型 | |
|---|---|---|---|
function(函数声明) | 是 | Actual function(实际函数) | Block |
var变量 | 是 | undefined | Function |
let和const变量 | 否 | <uninitialized>,TDZ | Block |
函数表达式和箭头函数 | 取决于函数表达式使用的类型 |
一个变量如果可以提升的话,我们就可以在声明前使用它,初始值是它被使用得出的值。
hi();
console.log(a);
function hi() {
console.log('Hi!');
}
var a = 100;
//最后控制台得出:
Hi!
undefinedlet和const是不会被提升的,但从技术上来说它们是被提升的,但是它们的值基本上设置为初始化,所以根本没有任何价值,在实际中提升就像根本没有发生过,相对的,我们说这些变量被放置在了TDZ(时间死区)中,这使我们无法在范围开始之前访问变量,见下例:

TDZ创造出来是为了更容易避免和获取错误,因为使用设置为未定义的变量在实际声明之前可能导致严重的错误,且错误很难找到。TDZ另一个作用就是使const变量按照它们实际应该工作的方式去工作,因为据我们已知,const不能重新分配新的值,所以首先将它们设置为未定义然后分配给它们真正的值是不可能的,所以TDZ是它的初始值,而不是像var一样工作。
现在看来提升好像造成了很多问题,但是为什么我们需要提升技术呢?
因为这样我们就可以在函数声明前去使用它,因为这对一些编程技术是十分重要的(缝合怪),比如互相递归,也有人认为这使代码更具可读性。
this关键字
this关键字或者说this变量实际上是一个特殊变量,它为每个执行上下文创建。
this关键字是动态的,下面方法this例子中会说明。
this | 初值/指向 |
|---|---|
方法 | 调用该方法的Object |
简单的函数调用 | undefined(只在严格模式下得到未定义,否则会指向window) |
箭头函数 | this周围的函数(lexical this)(箭头函数没有自己的this关键字) |
事件监听器 | DOM元素 |
new,call,apply,bind | 后面会详细讲到 |
方法的例子:
const jonas = {
name: 'Jonas',
year: 1989,
calcAge: function() {
return 2037 - this.year; //calcAge是一个方法 this->jonas year->1989
}
};
jonas.calcAge(); //48
//可以将对象中的方法指向另一个对象中
const matilda = {
year:2017
};
matilda.calcAge = jonas.calcAge; //函数本身也是一种变量,这里实际上是一种借用(引用)
matilda.calcAge(); //20
//但是为什么matilda对象中引用了jonas的对象方法,year也改变了呢,year应该仍然是1989才对啊?
//因为this是动态的,this被引用到matilda对象后,动态指向了matilda.year。简单函数调用的例子:
console.log(this); //Window
const calcAge = function (birthYear) {
console.log(2037 - birthYear);
console.log(this);
};
calcAge(1991); //46
//undefined(但这里是在严格模式下才这样,如果在简单模式这里应该还是Window)箭头函数的例子:
const calcAgeArrow = birthYear => {
console.log(2037 - birthYear);
console.log(this);
};
calcAgeArrow(1980); //57
//Window(因为箭头函数没有自己的this关键字,所以箭头函数只是使用 lexical的this关键字,也就是其父元素或者其父范围的this关键字,因为箭头 函数的父元素是全局,所以会得出Window)箭头函数方法的例子:
const jonas = {
firstName: 'Jonas',
year: 1991,
calcAge: function() {
console.log(2037 - this.year);
},
greet: () => console.log(`Hey ${this.firstName}`);
};
jonas.greet(); //Hey undefined
//按理来说应该得到Hey Jonas,为什么会这样呢?
//因为箭头函数方法是没有this关键字的,所以借用父元素的this关键字,它的父元素是Window,你可能认为其父元素应该是jonas Object才对,但是对象中的元素其实不是代码块它没有自己的作用域,它是一种对象字面量(Object literal)是我们从字面上定义对象的一种方式,所以这些都还在全球范围原始值和对象的存储方式区别
//这里我们期望保留oldAge的值
let age = 30;
let oldAge = age;
age = 31;
console.log(age); //31
console.log(oldAge); //30
//这里我们期望friend的age和me的age不一样
const me = {
name: 'Jonas',
age: 30,
};
const friend = me;
friend.age = 27;
console.log('Friend:', friend); //{name: "jonas", age:27}
console.log('Me:', me); //{name: "jonas", age:27}
//为什么是一样的呢?我们一开始学习JavaScript时学习了原值(原始类型)Number、String、Boolean、Undefined、Null、Symbol、BigInt。
后来学习的基本上都是一个对象。
因为原值和对象的引用类型方式不同它们存储在内存中的方式也不同。
现在我们回想JavaScript的runtime中的JS引擎的存储构造:
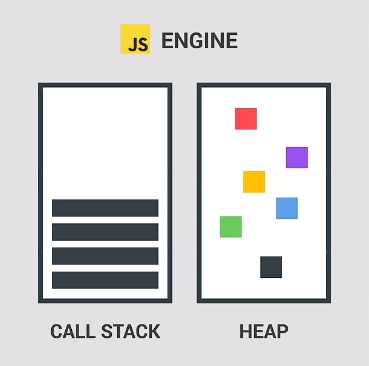
所有的元素要么存在堆中要么存在栈中,那么这两者有什么不同才造就了现在原值和对象的存储区别呢?
所有的对象或者说引用类型都被存放在堆中。
所有的原值或者说原始类型都被存放在栈中。(但其实是先放在执行上下文声明的,这里参考执行上下文)
前面代码在堆和栈中的大致变化:

这里建议看原片解释就够了,十分详细清楚。
既然对象中的值只能引用,那我们应该如何复制对象中的值呢?我们可以这样:
//现在假设有一名女士姓Williams,嫁人后需随父姓Davis
let lastName = 'Williams';
let oldLastName = lastName;
lastName = 'Davis';
console.log(lastName, oldLastName); //Williams, Davis 我们用变量当然可以改变
//但在对象中就不行了
const jessica = {
firstName: 'Jessica',
lastName: 'Williams',
age: 27,
};
const marriedJessica = jessica;
marriedJessica.lastName = 'Davis';
console.log('Before marriage:', jessica);
console.log('After marriage:', marriedJessica);
//Before marriage:{firstName: 'Jessica', lastName: 'Williams', age: 27}
//After marriage:{firstName: 'Jessica', lastName: 'Williams', age: 27}
//这两个对象是指向的同一个堆内存地址,所以输出是一样的
//那我们如何改变呢?现在我需要将jessica2中的值复制到jessicaCopy中,并改变它的属性lastName的值
const jessica2 = {
firstName: 'Jessica',
lastName: 'Williams',
age: 27,
};
//Object.assign()方法本质上是将一个对象和另一个对象合并放入一个新的对象当中去,这种特性被程序员用来复制对象值了
const jessicaCopy = Object.assign({}, jessica2);
jessicaCopy.lastName = 'Davis';
console.log('Before marriage:', jessica2);
console.log('After marriage:', jessicaCopy);
//Before marriage:{firstName: 'Jessica', lastName: 'Williams', age: 27}
//After marriage:{firstName: 'Jessica', lastName: 'Davis', age: 27}
//现在输出就不同了,但是这种技术仅限于第一层,若一个对象中还有一个对象那么这种方法就没有用了,我们可以称Object.assign()只能创建一个浅拷贝如果需要深度克隆来克隆对象中的对象我们需要用到外部库中的深度克隆,在之后我们会学习。